


Transformers In Scikit Learn
Transformers as the name implies are used to transform objects. In Machine Learning, transformers are used to transform data into a desired format. If you new to Machine Learning, you can check this article out. Transformers are models that process and transform a data set. These transformers are very useful because rarely is our data in a form to feed directly to a machine learning model for both training and predicting. For example, a lot of machine learning models work best when the features have similar scales. All transformers in Scikit Learn have the same interface:
- fit(X): trains/fits the object to the feature matrix X .
- transform(X): applies the transformation on X using any parameters learned
- fit_transform(X): applies both fit(X) and then transform(X).
A transformer may or may not create extra feature and some transformers can even reduce the number of features in the data. Examples of transformers in Machine Learning are Standard Scalar or Normalizer, Vectorizer and Tokenizer, PCA, etc. Transformers like Standard Scalar, Mim-Max Scalar etc don't change the number of features whereas Polynomial Features is an example of a transformer that creates a new feature and RFE, Select K best etc reduces the number of features.

Objectives
At the end of this article, you'll be able to :
- You'll learn how to use Scikit Learn transformers,
- use multiple transformers in a single pipeline,
- build your own custom transformers that behaves like a Scikit Learn transformers, and
- build a simple regression model.

Before we go further, I'll like to explain briefly what Scikit Learn is. Scikit Learn is a Machine Learning library and it consists of a lot of algorithms used for shallow learning problems like regression, classification, clustering etc and also has packages for neural networks also. Scikit Learn is very popular due to it's easy to use structure.
Now let's get started.
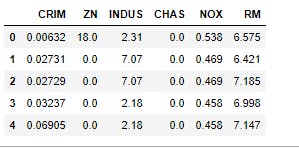
Firstly, let's get turn our raw data to a dataframe, for simplicity, I'll be using a dataset that is available in sklearn.
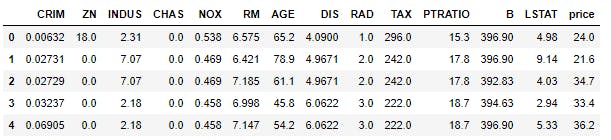
In the code snippet above, I first import the libraries that I'll be using to get the data from sklearn and turn it to a dataframe. I then transformed the data and turned it to a dataframe using pandas.Pandas is a popular Python package for data science, and with good reason: it offers powerful, expressive and flexible data structures that make data manipulation and analysis easy, among many other things. The DataFrame is one of these structures, you can check this article on pandas out. Looking at the data, the features are in different scales, it'll be necessary to change the data by turning all features to the same scale. I'll thus turn the data to a unit variance and zero mean data using the Standard Scalar of Scikit Learn. Note that the variance may not be exactly 1 and the mean may also not be exactly 0 but they'll be close to 1 and 0 respectively.
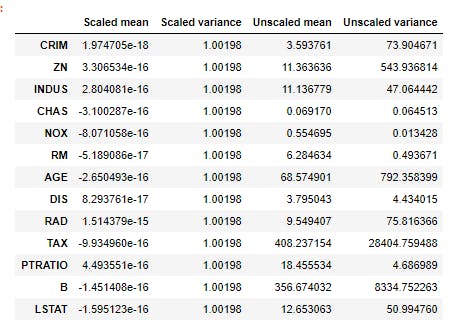
Having done this we've been able to transform our data to be in a desired format.
Using multiple transformers
Preprocessing is one key feature of Machine Learning since real world data won't be clean as a result we'll be needing multiple transformers. In this data, we might want to do the following:
- create polynomial features,
- scale the data,
- and reduce the dimensionality of the data using PCA(principal component analysis). PCA has to deal with choosing only important features from the total features. You can read up on PCA here .
To achieve this we might want to do:
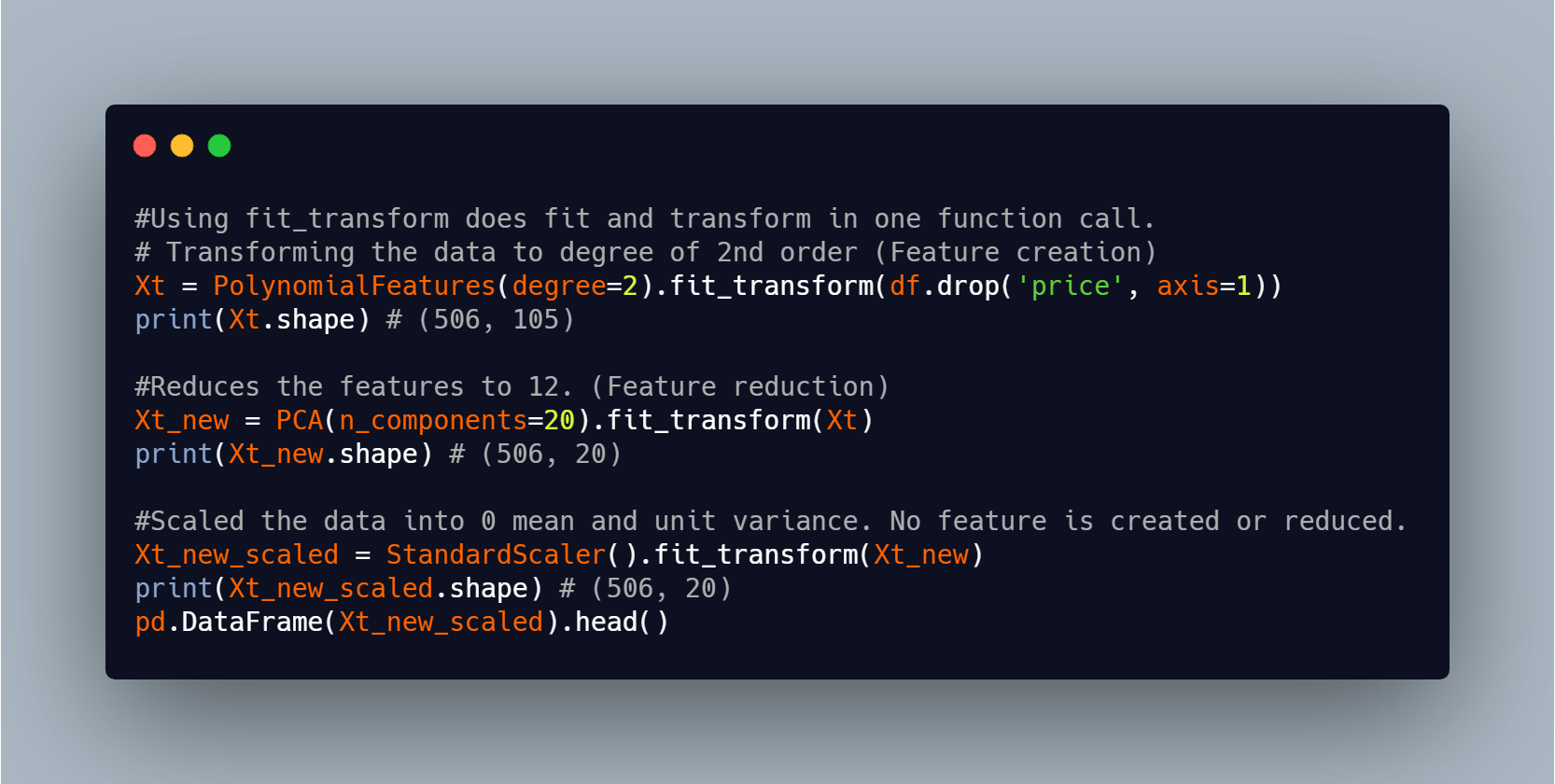

This technique isn't advisable as we'll need to keep track of previous variables and it's also error prone. It'll be cumbersome to do something like this if we'll be doing many transformations on the data.
Pipelines to the rescue.
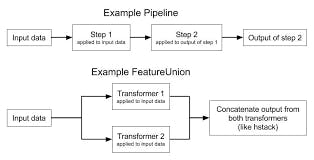
As our analysis and workflow becomes more complicated, we need a tool that helps with scaling up. For example, you may need to apply multiple transformations to your data before it is ready for a supervised machine learning model. You can apply the transformations explicitly, creating intermediate variables of the transformed data. Pipelines are an approach that helps prevent keeping track of intermediate transformations and help scale our code for more complicated analysis. Pipelines are made with the Pipeline class. Essentially, a pipeline is an estimator object that holds a series of transformers with or without a final estimator. Apart from pipelines, Scikit Learn has column transformers and feature unions which does similar task only that it isn't done in a sequential order .
- Pipeline is to series as Feature union is to parallel.
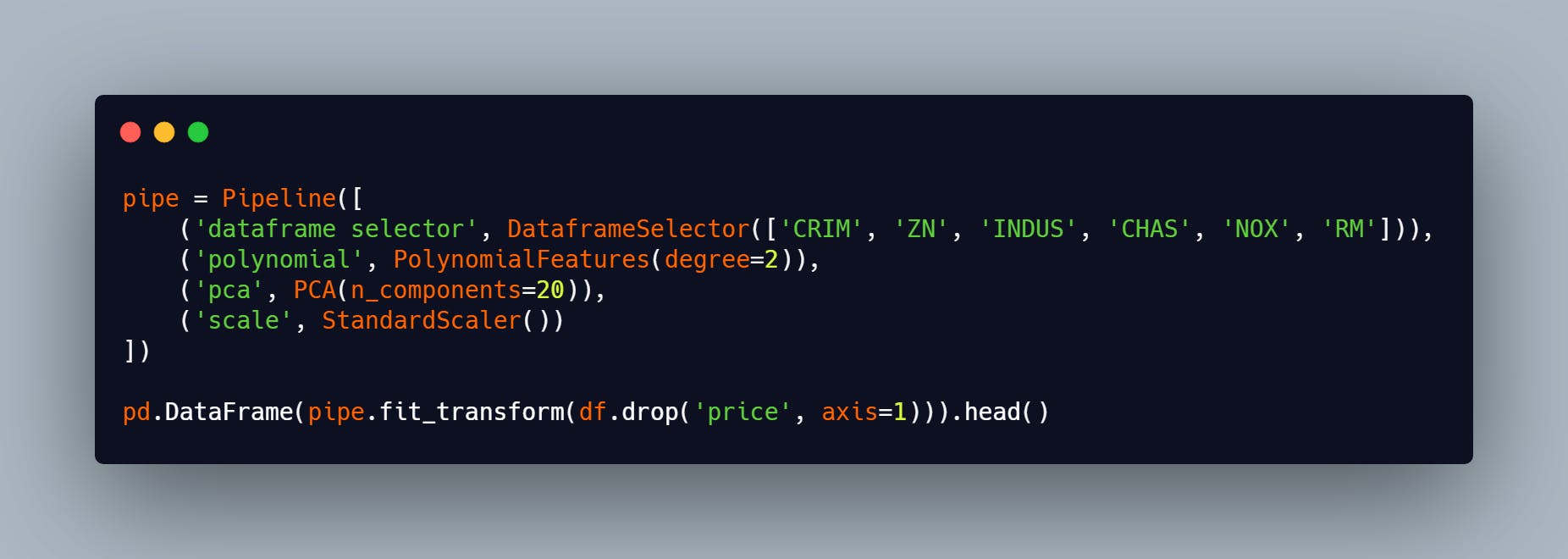
Let's implement the above transformations with a pipeline :
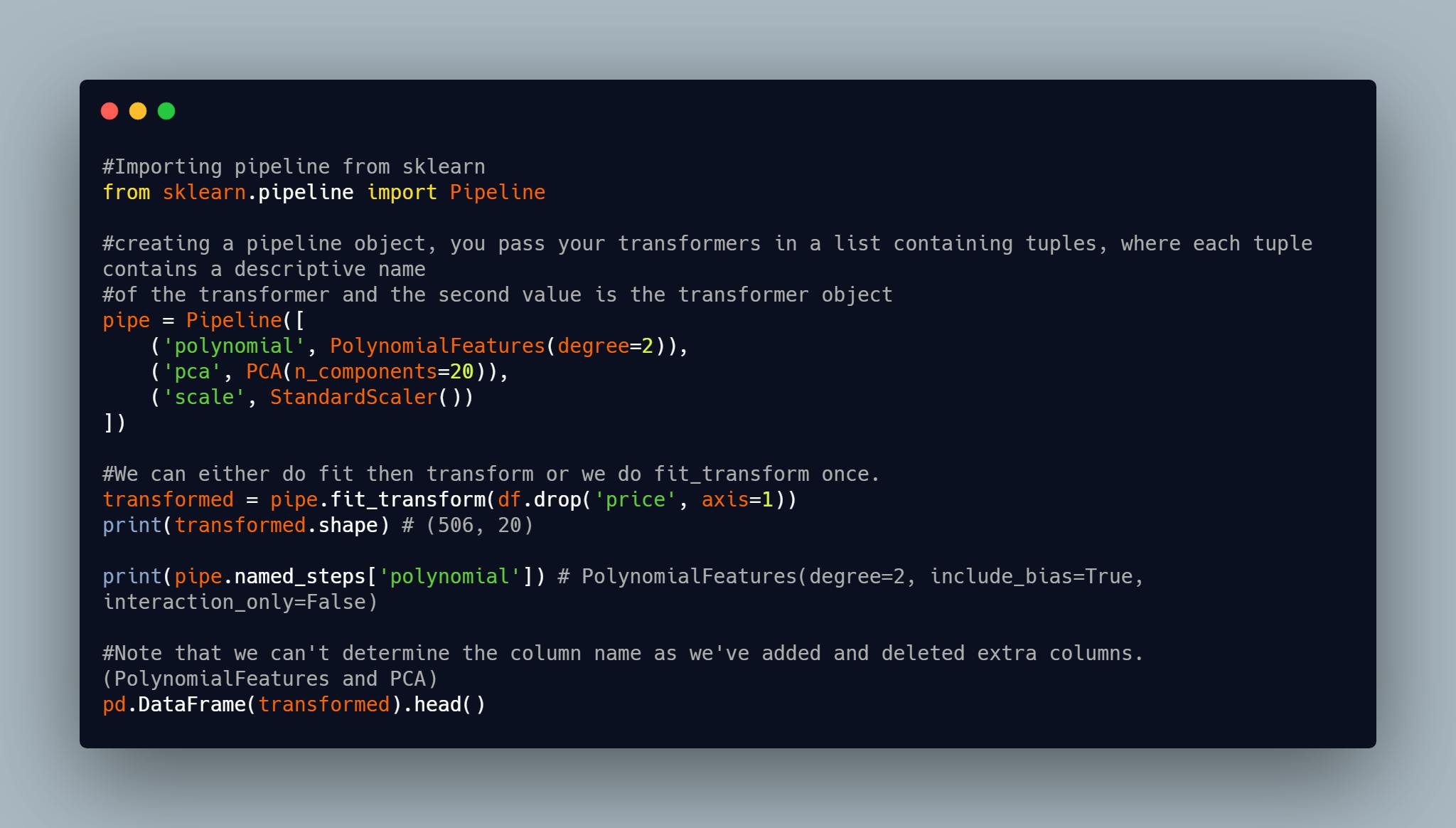

From the code above, we pass a list of tuple to the pipeline object. Each tuple takes two values a string and a transformer object, the string can be anything but needs to be descriptive. Pipelines are built in such a way that the output(transformed data) of the first object in the list passed into it and goes on like that till the last object in the list. Note that a pipeline can have a predictor in it, but it has to be the last value. Also a pipeline has the following interface:
- fit(X): trains/fits the object to the feature matrix X starting from the first transformer to the last estimator(transformer or predictor) .
- transform(X): applies the transformation on X using any parameters learned starting from the first transformer to the last estimator(transformer or predictor) .
- fit_transform(X): applies both fit(X) and then transform(X). starting from the first transformer to the last estimator(transformer or predictor) .
- named_steps: This method is a dictionary where each key is the name given to each estimator in the pipeline while each value is the estimator itself. This method helps to debug.
Building custom transformers
We've seen how to use transformers in Scikit Learn.While scikit-learn provides an abundance of machine learning models and transformers, it sometimes may not provide us a specific model or transformer our workflow requires. However, through the concept of inheritance, we can build a custom estimator that will be compatible with the infrastructure of scikit-learn. For example, we want our custom model to have the fit, and either predict or transform methods. Compliance with scikit-learn is essential if we want to use our custom model with things like the Pipeline and GridSearchCV class. In the example below, we will create a custom transformer that takes a list as it's constructor and returns a dataframe where the list contains the column names of the new dataframe.
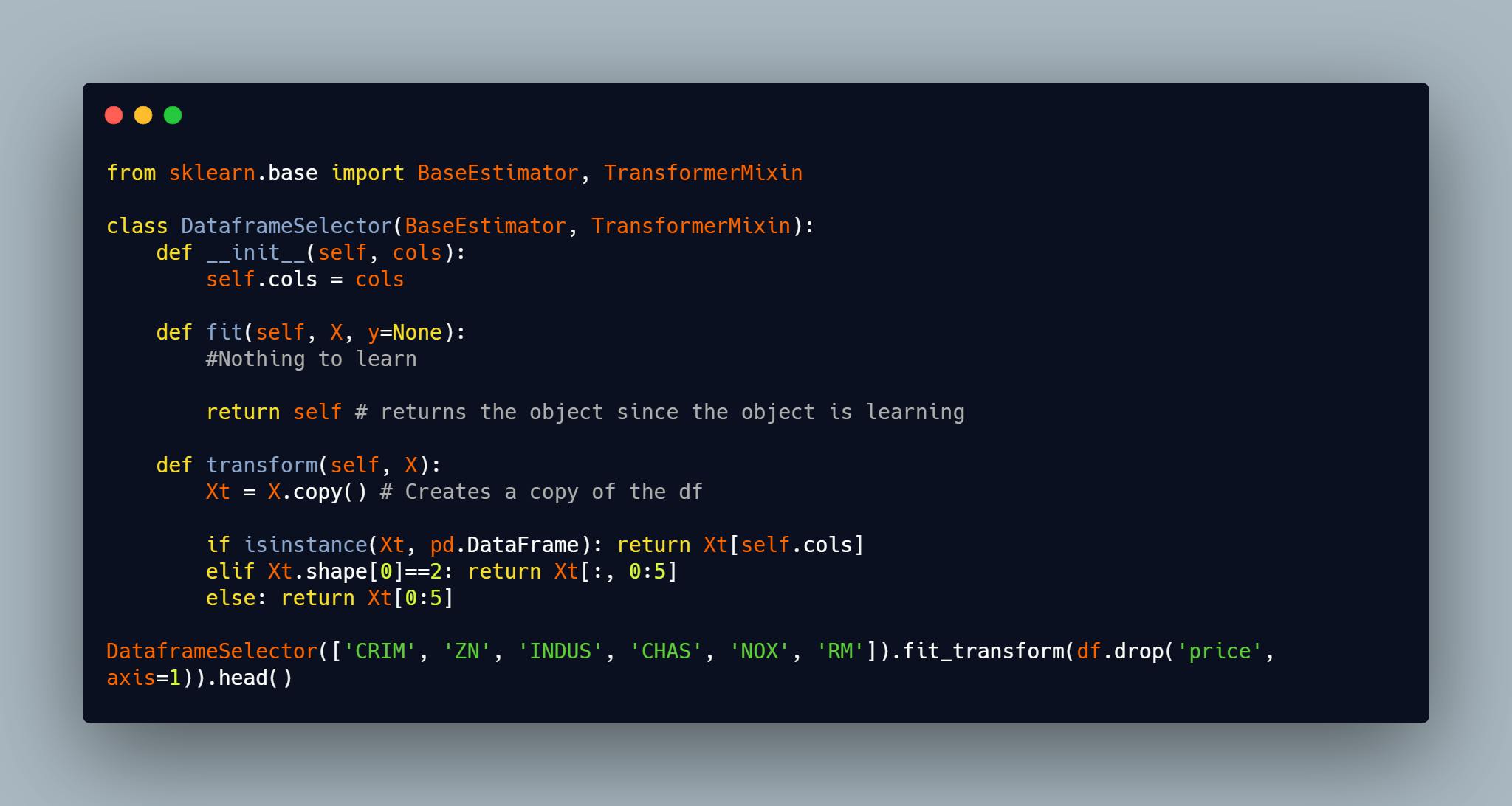
The class inherits from two objects BaseEstimator and TransformerMixin which is why we do not need to define a fit_transform method before using it and we can also use the object in a Pipeline, Feature Union etc. In the example above, we created 3 functions within the object:
- init dunder method which is used to initialize the object since we're working with Object Oriented Programming.
- fit which is where the algorithm learns, and we always return self. Note that even though I didn't add anything there(since there's no learning) I still defined it. You'll notice that I set y to None, this is the convention for Scikit Learn estimators, transformers need not to learn anything from the target but predictors needs to learn from the target alongside the features, but if our transformer needs to learn anything from the target variable we can always add it as a parameter when calling the fit or fit_transform method and we'll use it in the function where necessary also.
- transform which is where the transformation is taking place, since our transformer doesn't need the target variable we did not bother adding it as a parameter in this method, it all depends on the task at hand.. Note that how you create your function will determine how it'll be used. You can't create a function with two arguments and call it with one argument. Note: we can add helper functions if our task requires it, but they need to be called in the transform method since that's where transformations takes place. Going back to our first pipeline above, we'll use the DataframeSelector object to select some columns which is what we'll transform and use in our machine learning workflow.

Building a simple regression model
So far we've been able to transform our features, but machine learning isn't just about feature transformation. We want to make computers learn from previous data and make predictions on unseen data. We'll build a simple regression model using the LinearRegression object in Scikit Learn, you ca check this article out if you want to understand more about regression in Machine Learning.
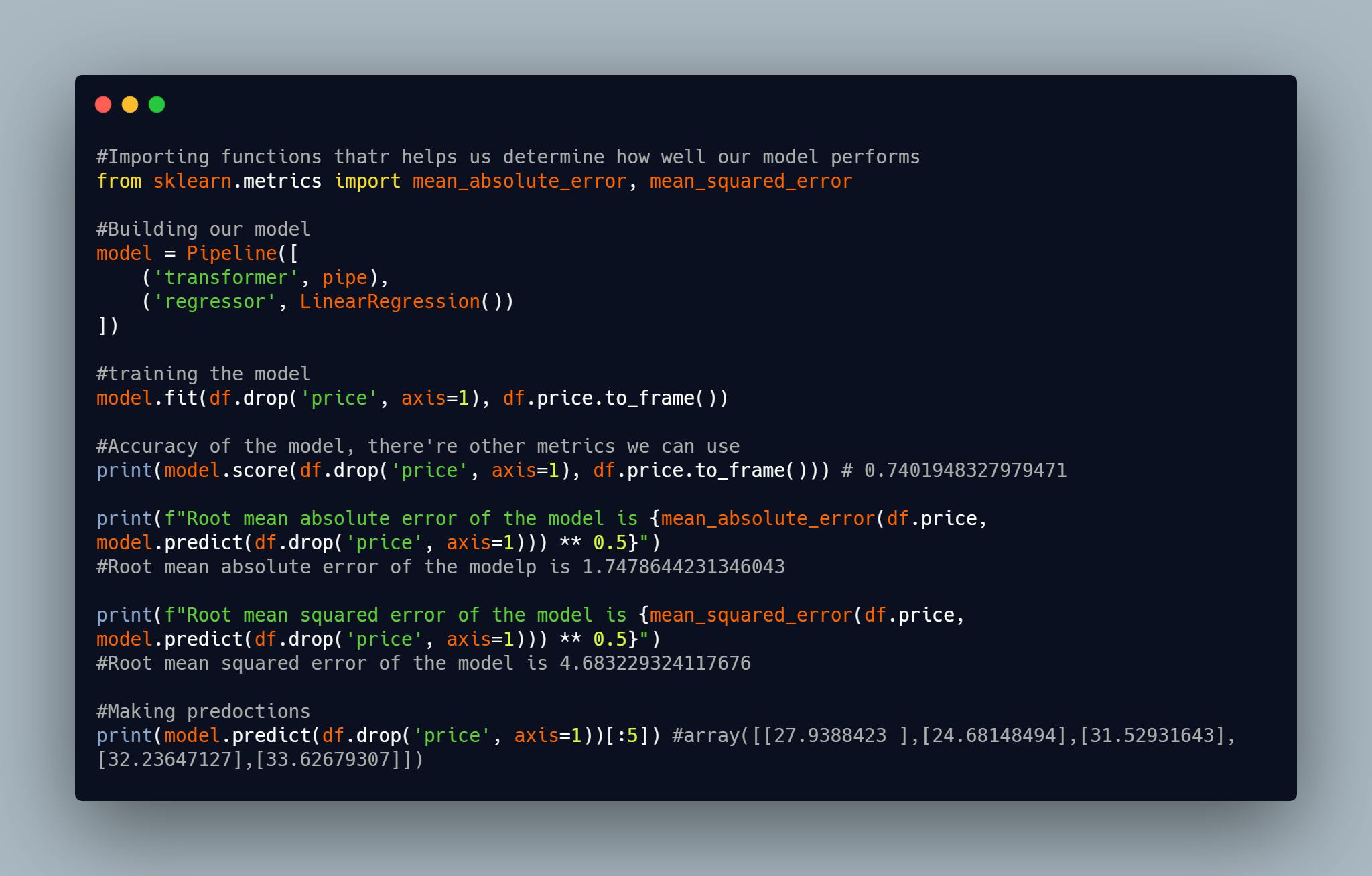
In the above code snippet, we pass the previous pipeline which does all the transformations and also pass our regressor to the pipeline. We did the following:
- fit: we transform the data and pass the transformed data to the regressor and train the model all in one function call, note that we can't do fit_transform since a regressor ends the pipeline.
- score: or any other suitable metrics that works best for our data to check how well your model performs.
- repeat step 1 and 2 till you get a desirable accuracy.
- predict: We make predictions using the trained model.
Note that I didn't perform step 3 as it isn't the goal of this article. Step 3 involves, changing the regressor to a better one or tuning the hyperparameters of the regressor to get a better score.
Conclusion
This article has walked you through how to use transformers in Scikit Learn, implementing transformers in Pipelines, how to your build custom transformers with Scikit Learn and how to build a base regression model in Scikit Learn. You can create a custom transformer that selects the n best correlated features using the Spearman test in a dataframe and returns a new dataframe where the columns are the features and the values are the value in the original dataframe. This github repo might be of help. Work on the dataset again using this features instead, and let's see how well our model will perform. I'll love to hear from you in the comment section.
Happy Happy Data Science